
VIVA - Improving the Intake Process for Genomic Data
Goal
Design a user interface that allows users to upload and set up complex genomic data for analysis.
Background
VIVA is a controlled data commons web application created by Cincinnati Children's Center for Pediatric Genomics (CpG) to empower genomic research across Cincinnati Children's.
Team
Peter White, PhD Principal Investigator, Krishna Roskin, PhD Co-Principal Investigator, Michael Furgason, PhD Data Strategy, Philip Dexheimer Bioinformatician, Andrew Rupert Software Architect, Nicholas Felicelli Software Architect, Adriana Navarro UX Design and Research.
Timeline January - July 2019
Discovery
Kicked off the project with a participatory workshop to discuss as a team specific goals for the intake process and to go over unanswered questions about the overall application as well.

Conducted semistructured interviews with six end users ranging from medical doctors from various specialities to data analysts. The interviews focused on gaining a better understanding of current user experience uploading data but also discussed the overall application. Employed affinity diagramming to find patterns out of data clusters.

Identify
Who are we designing for?
Informed by user interviews, we identified four types of end users: clinicians, bioinformaticians, investigators, and developers. The personas below illustrate main traits, goals and how these four users will primarily interact with the app.





What are we improving?
Research suggested that the most problematic part of the experience was when users upload their data to the app. This initial step was crucial for users to dive into analysis and discovery. As a team, we decided to prioritize this part of the user experience. The diagram below lays out the existing intake flow as an exercise to analyze and find opportunities for improvement.

Design
Through the persona-building process, we realized that users had different levels of understanding as they came from very different backgrounds. To cover the needs of all users and make the intake process smooth, we employed a pipeline approach. All pipelines available will be listed up-front along with their features. This would help users make a better decision on what pipeline they need before uploading any data.

Wireframing and Testing
Following the user flow above, a set of wireframes were created for the first round of testing. Using cognitive walkthrough, we tested a medium fidelity prototype with eight participants who represented the persona profiles. Participants were asked to create a new WES project, upload files, and match normal-tumor samples during the test.











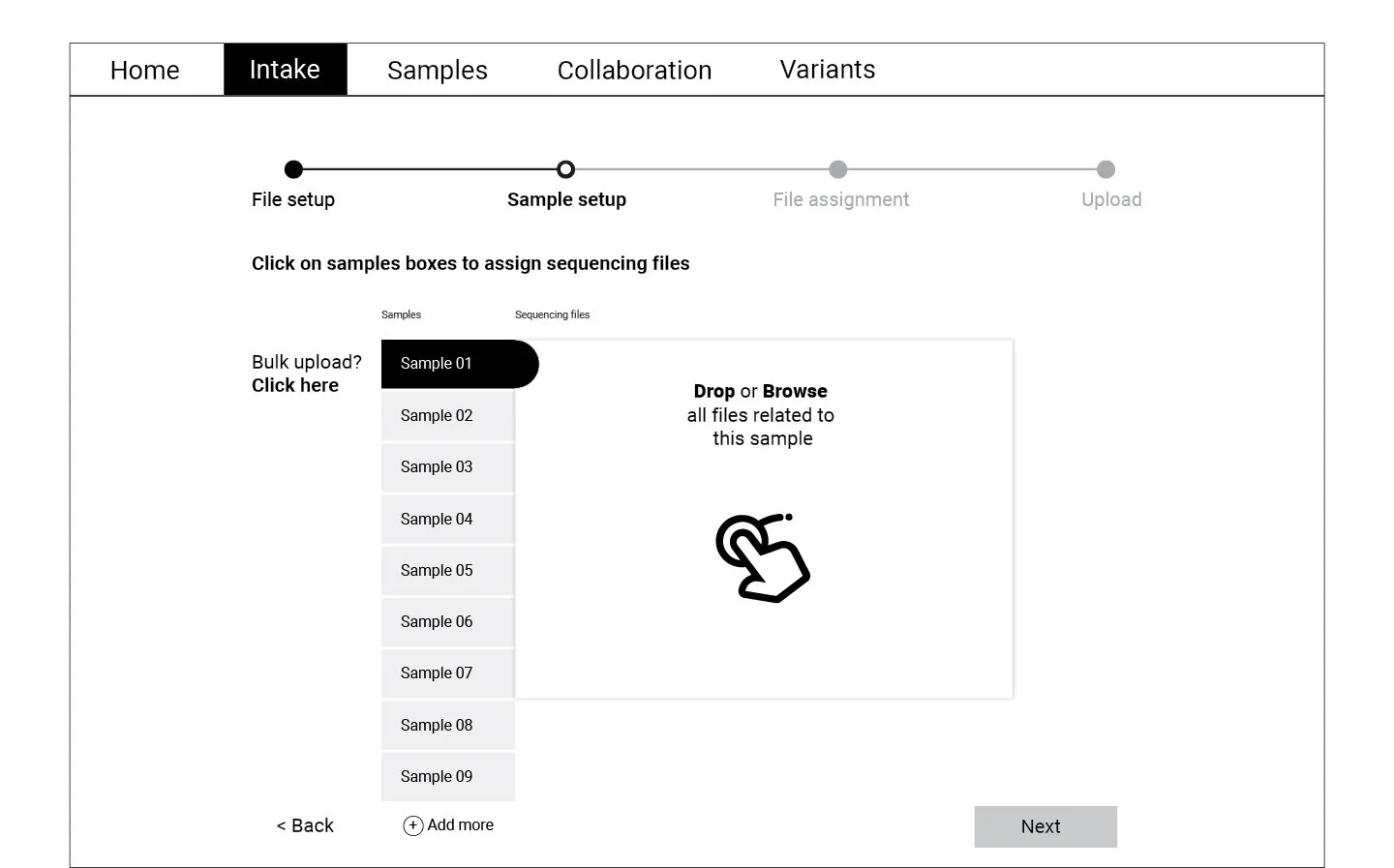








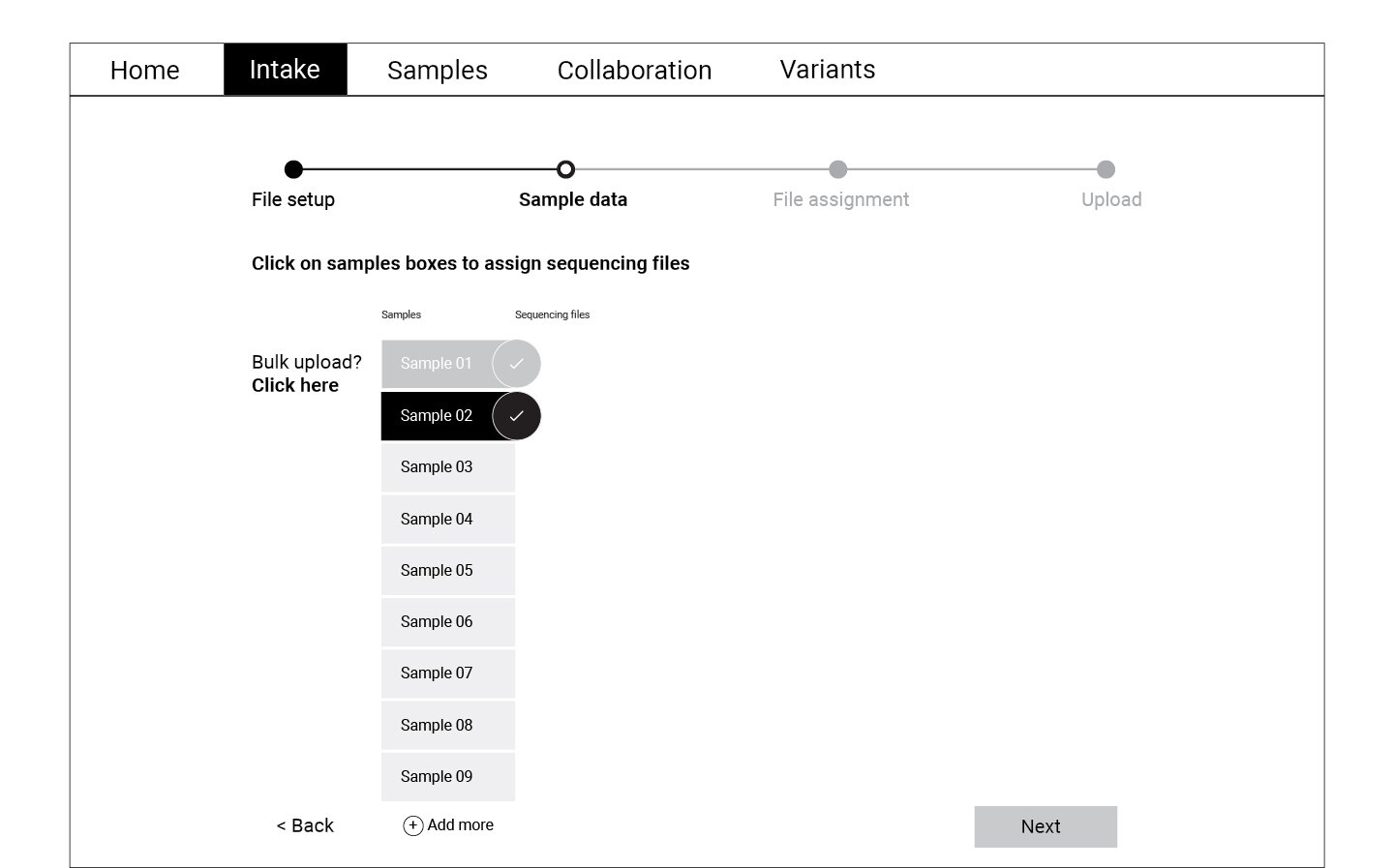



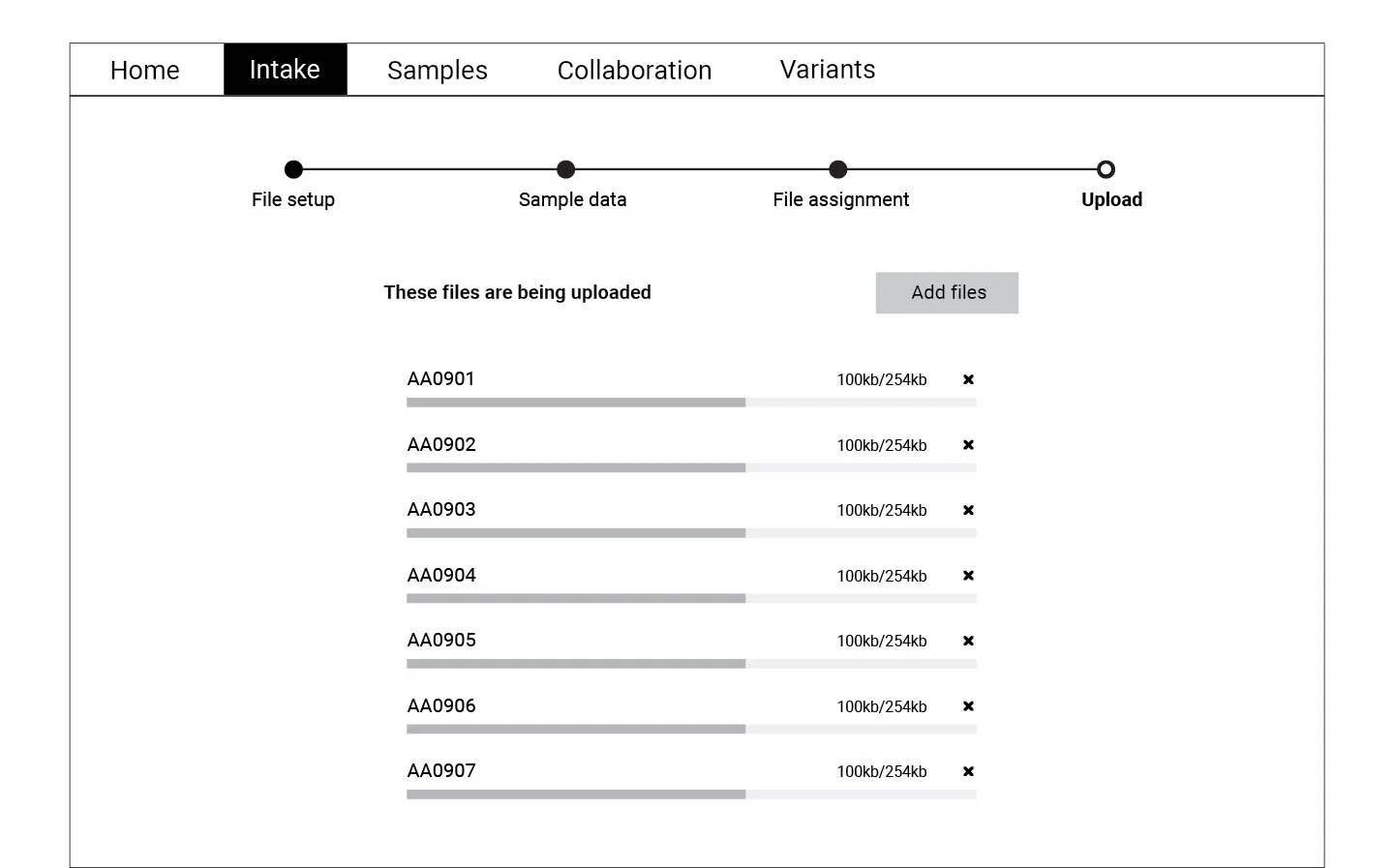










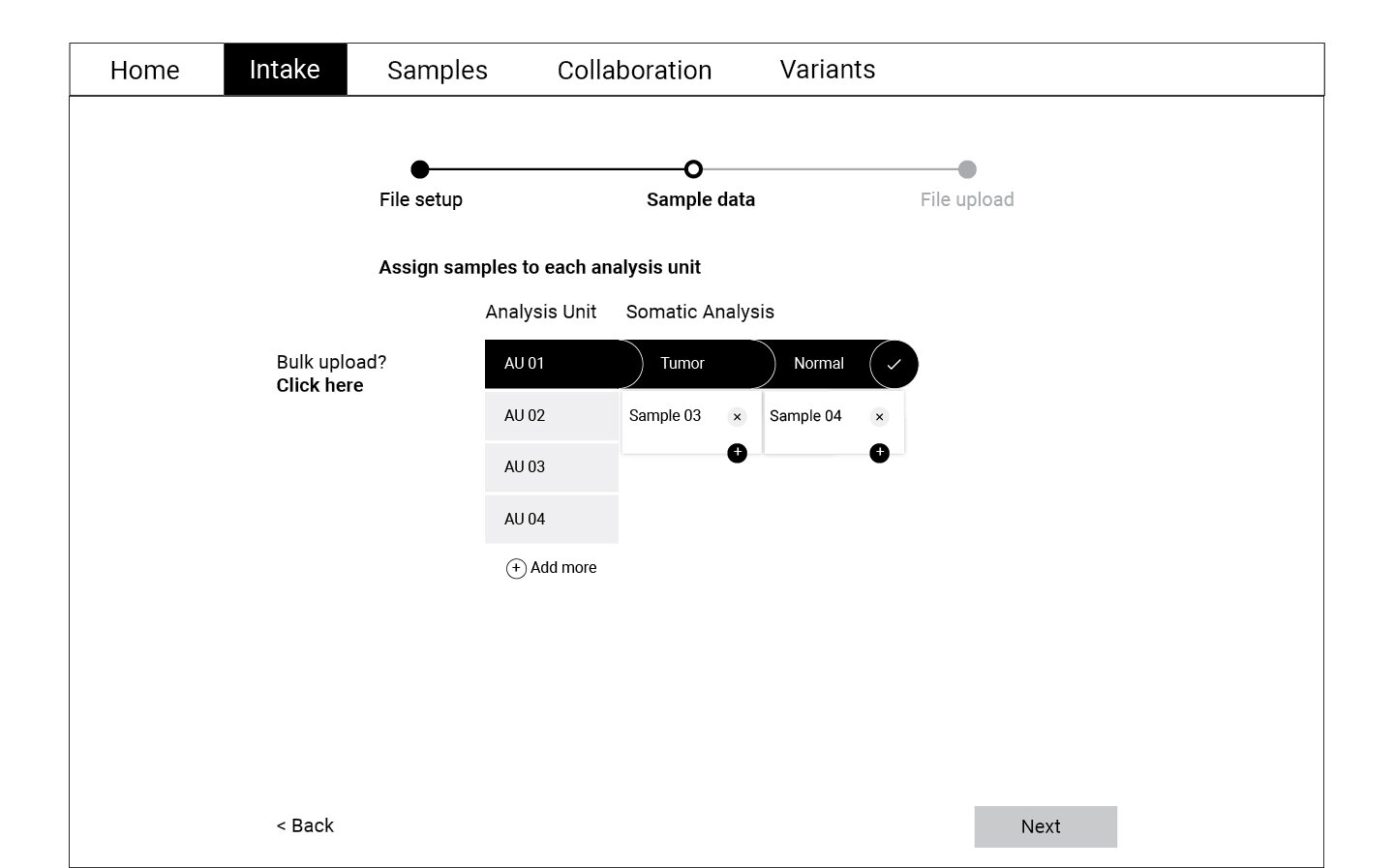






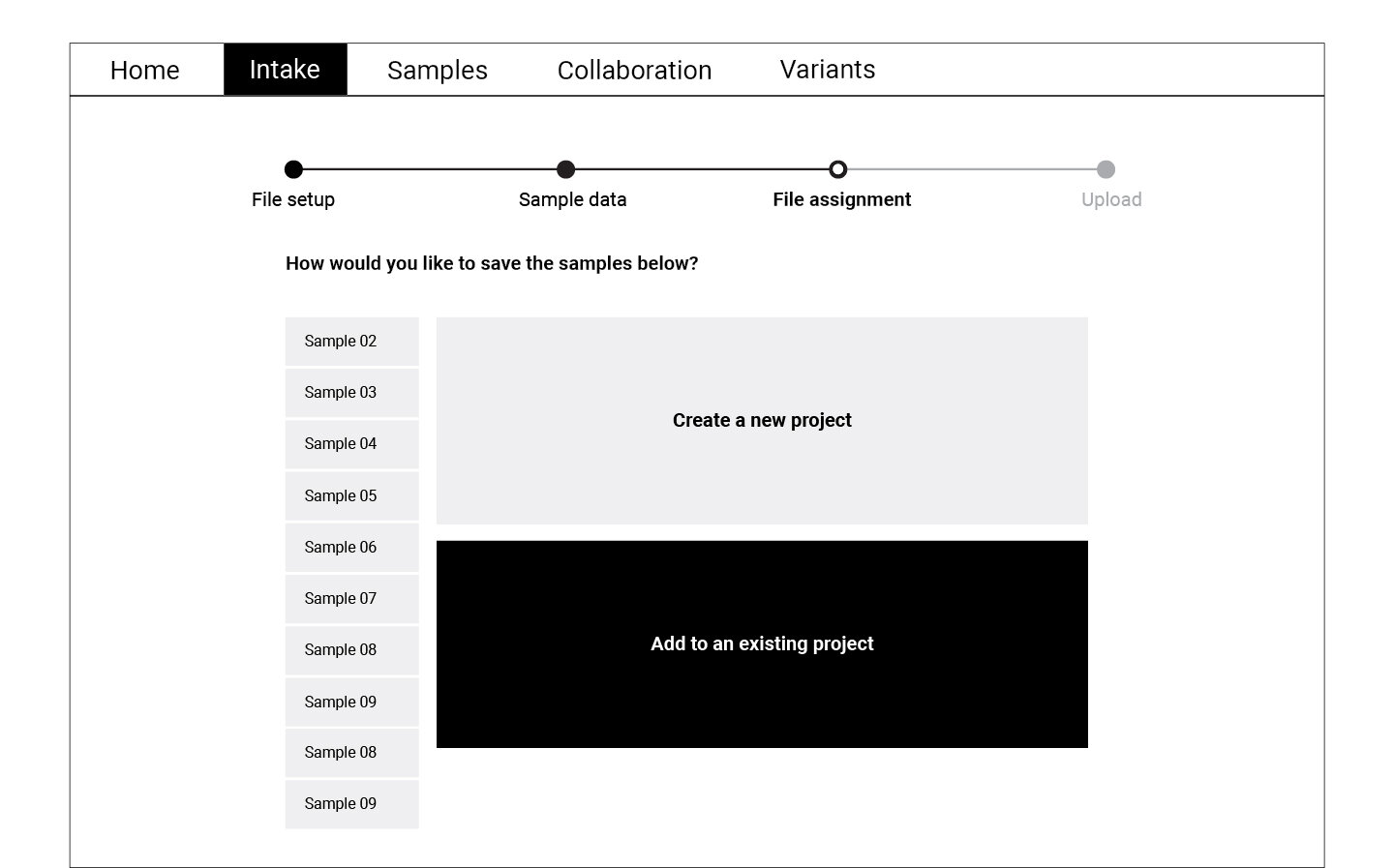






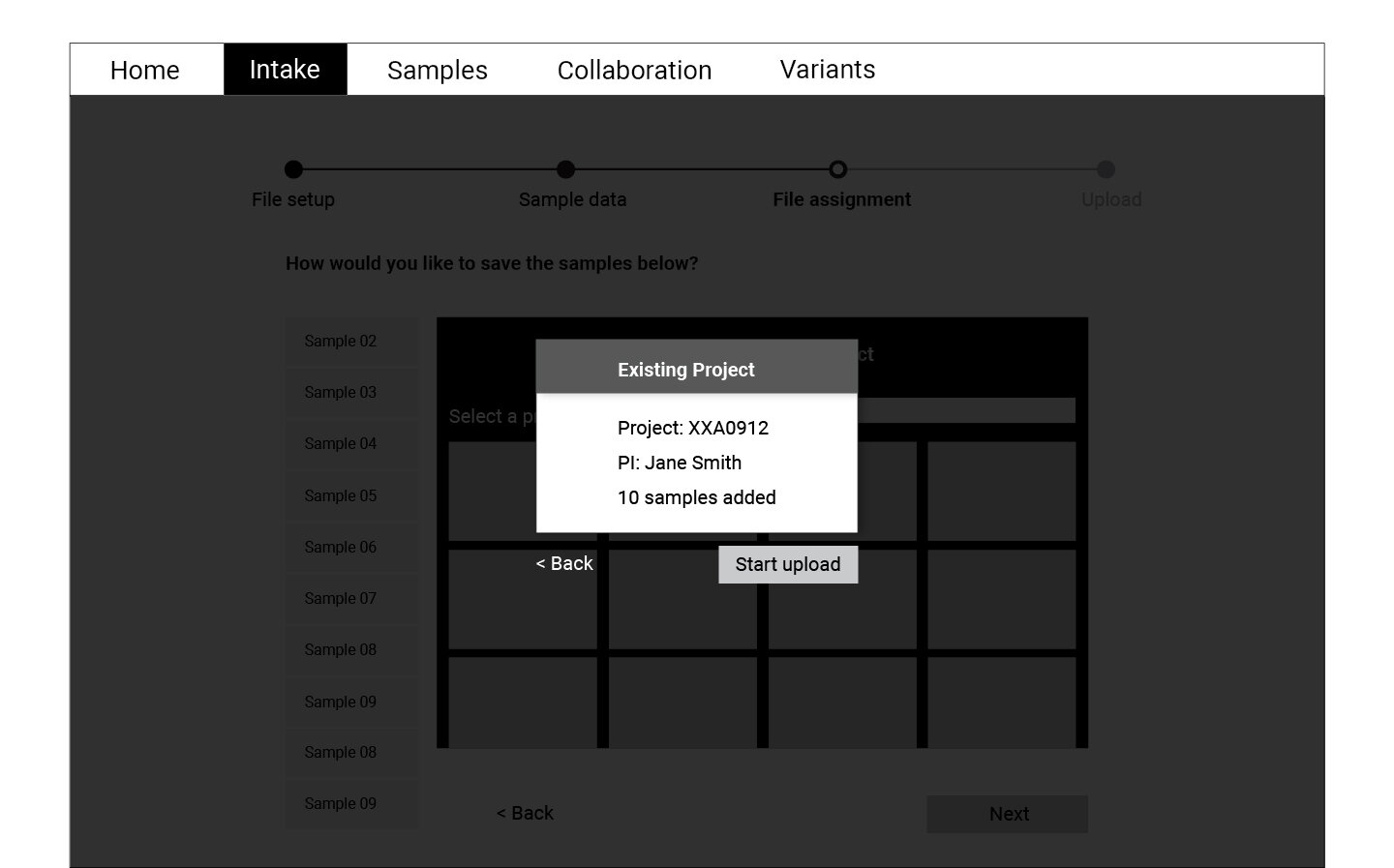
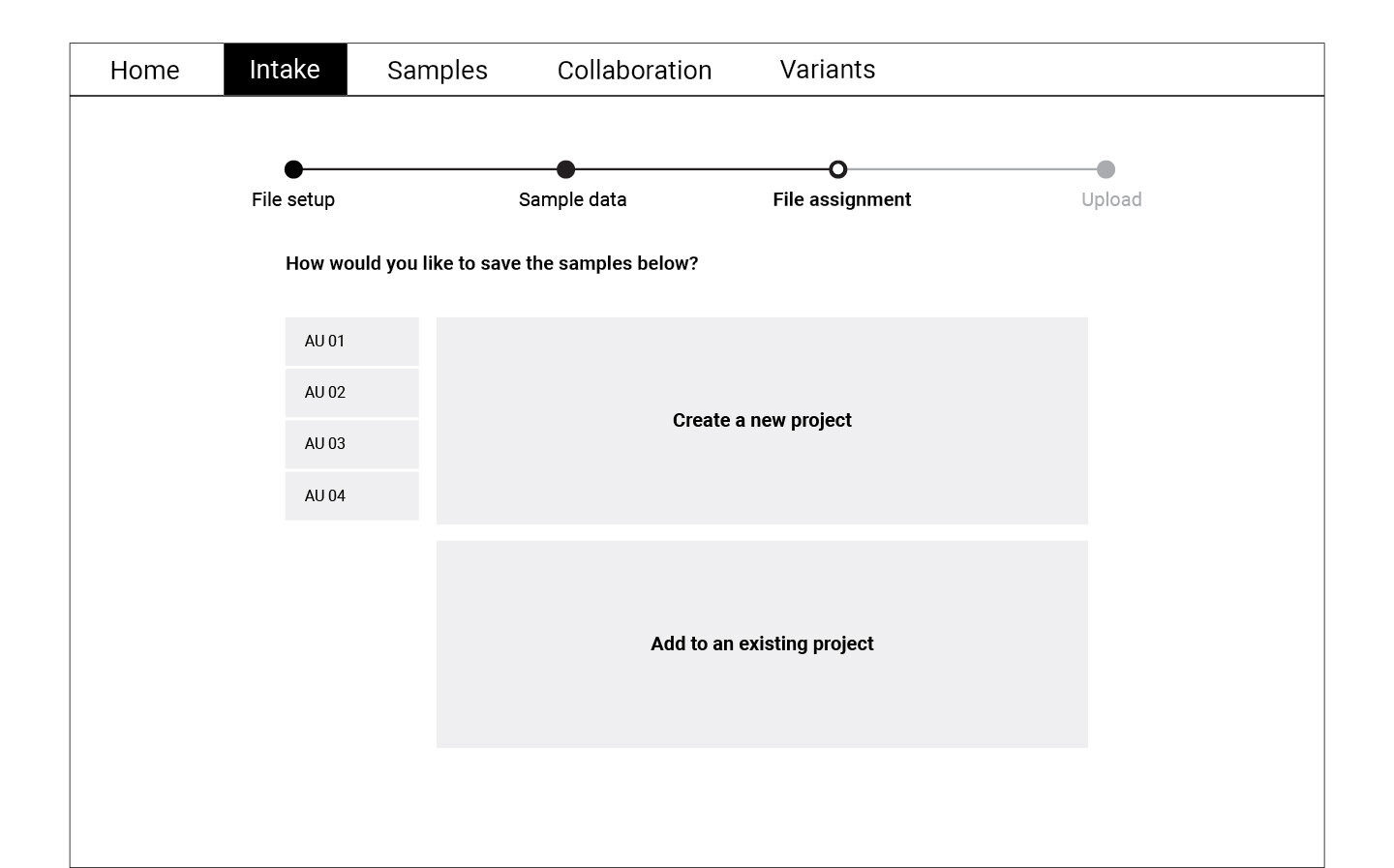
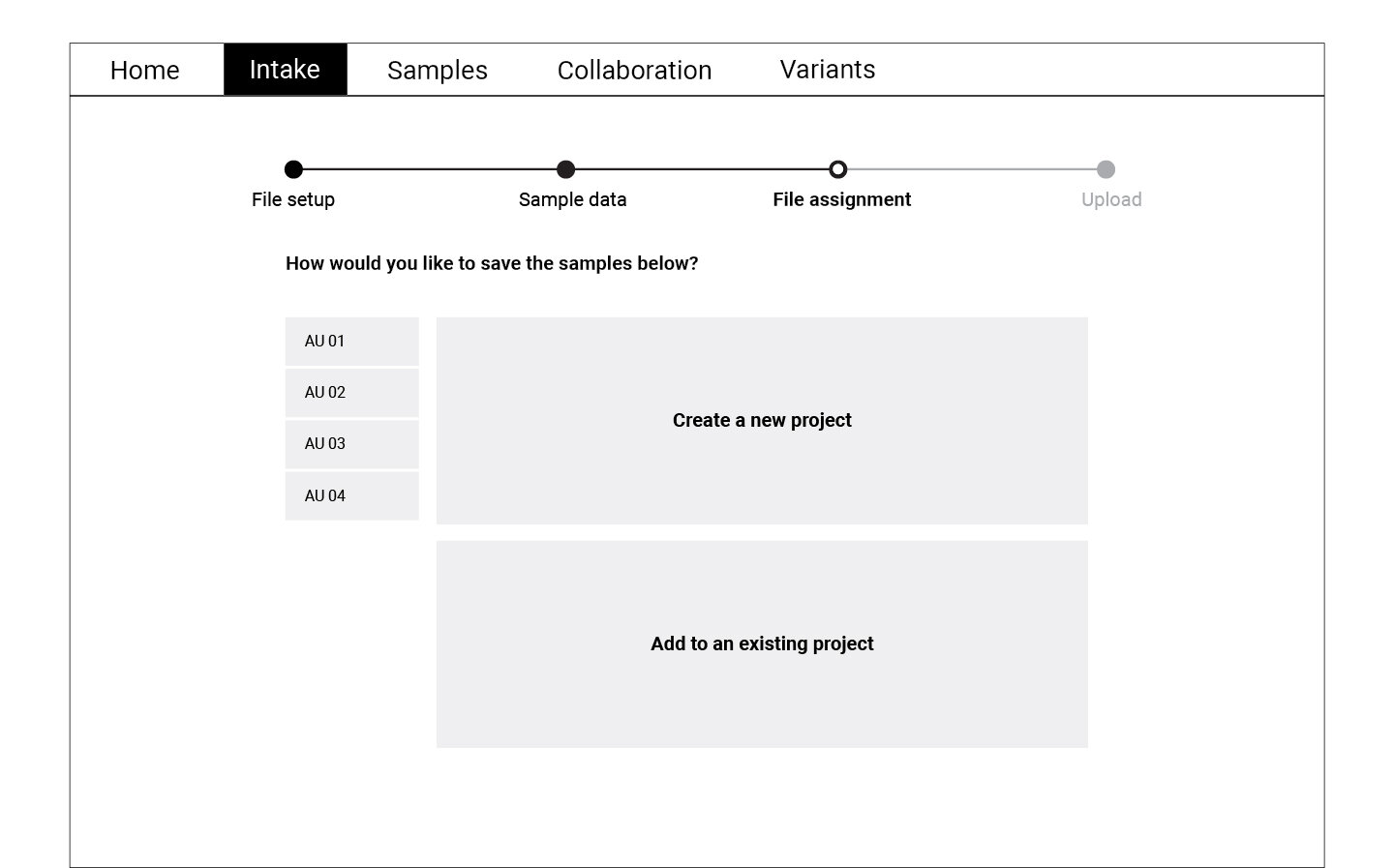


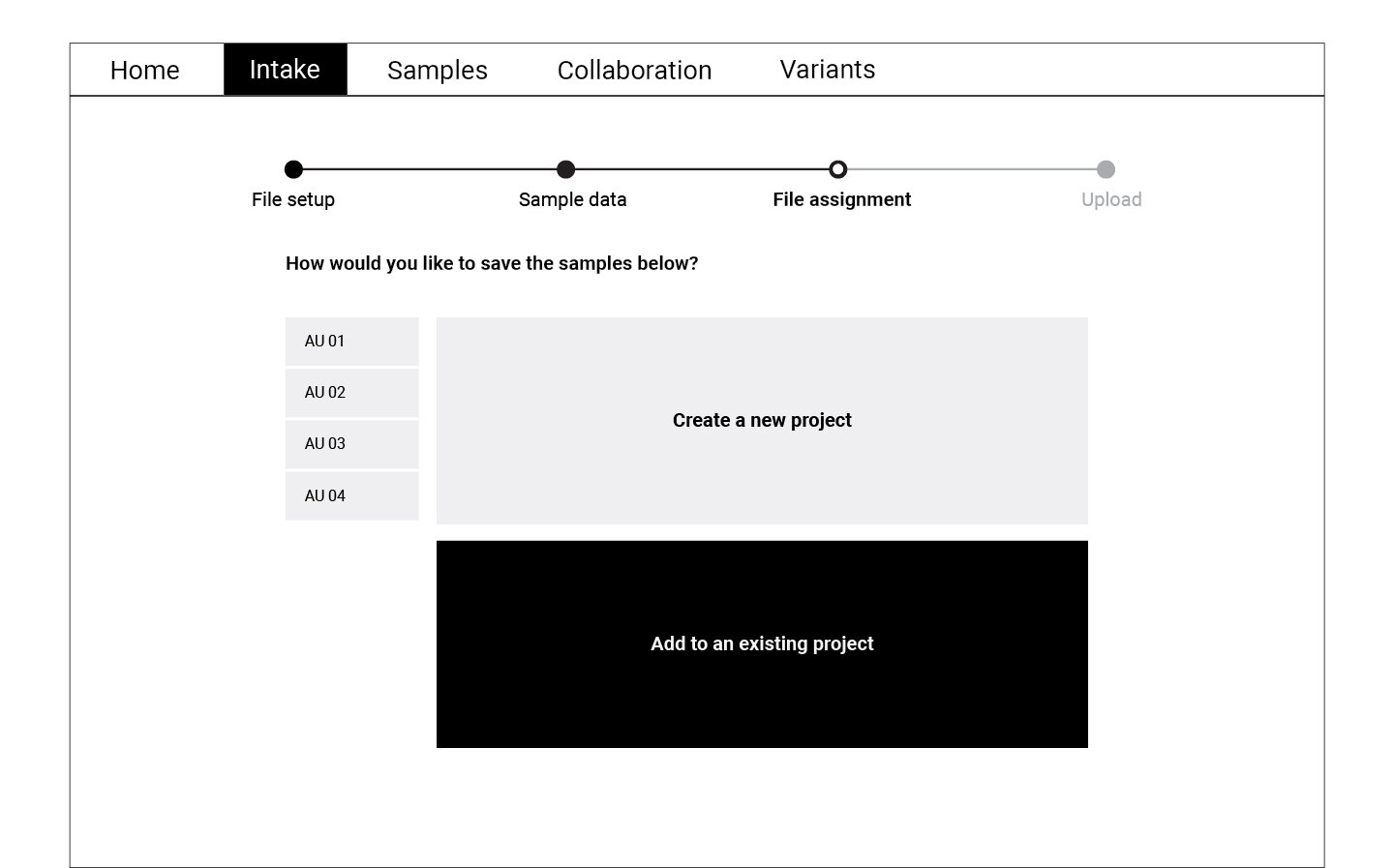





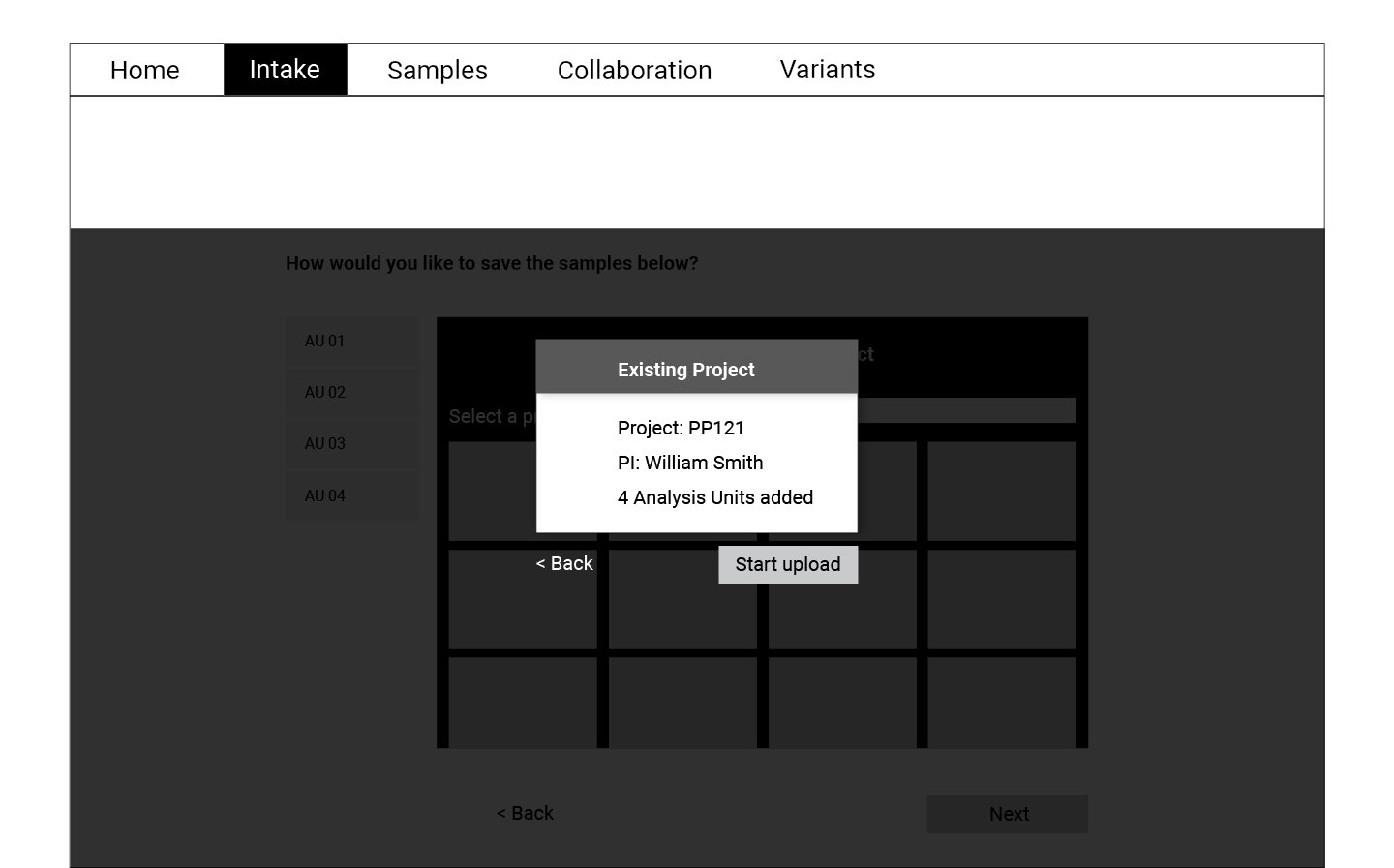





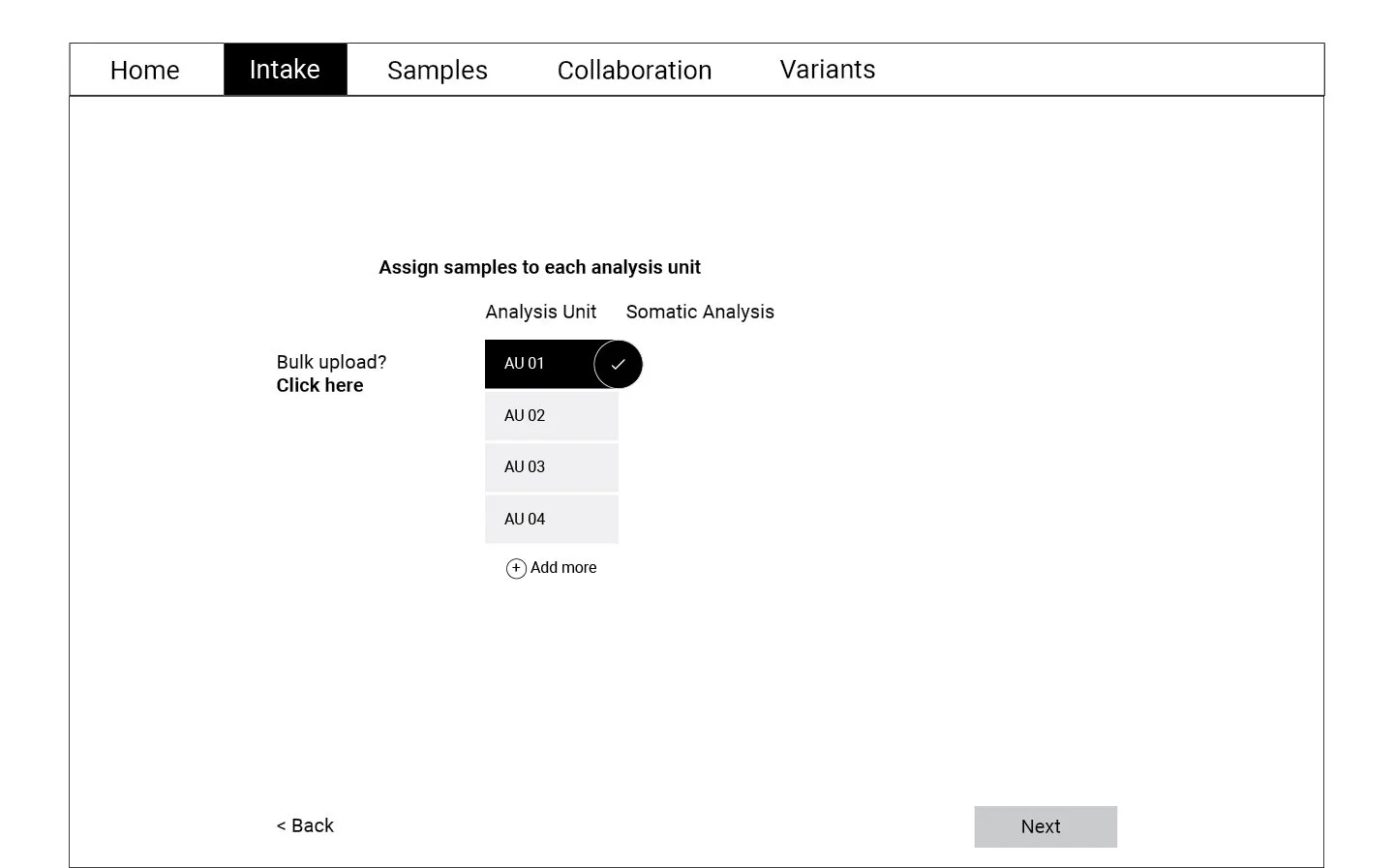

Refining and Testing
The data collected through the cognitive walkthrough was categorized as success or failure stories for each of the actions we asked participants to complete. Key insights from this analysis informed the refined version of the wireframes displayed below. These wireframes were translated into a high fidelity prototype which was again tested with a smaller group of participants.















Final Prototype
Through the second round of testing, we identified potential pain-points for users to successfully upload their data and refined the user experience by incorporating these insights. The video below displays an overview of the final intake process. At this point, the development team was provided with a user experience packet (user journeys, UI assets, style guide, personas, and prototypes) to get started with implementation efforts.
